This website uses cookies
For the proper functioning and anonymous analysis of our website, we place necessary and functional cookies,
which have no consequences for your privacy.
We use more cookies, for example to make our website more relevant to you,
to make it possible to share content via social media and to show you relevant advertisements on third-party websites.
These cookies may collect data outside of our website. By clicking "Accept" By clicking you agree to the placing of these cookies.
You can find more information in our cookie policy.

You can apply untill april 14th. After this date we will carefully check all the applications. Pre redundants have priority.
Ensure the stability, scalability, and performance of critical systems by implementing monitoring tools and automation.
Work independently while collaborating in a cross-functional team to solve diverse technical challenges.
Why choose Eneco?
As a key leader in system reliability, you will design and implement scalable, reliable solutions while mentoring junior engineers and collaborating across teams. You will lead cloud architecture initiatives, define release management strategies, and drive operational excellence. Your expertise will ensure proactive risk identification, system observability, and continuous improvement of critical platforms.
What you’ll do
You will play a key role in maintaining and improving the reliability of critical systems. Your work will involve implementing monitoring solutions, troubleshooting issues, and contributing to automation efforts. You will design small-scale cloud infrastructure, develop CI/CD pipelines, and define basic SLOs/SLIs. You’ll also mentor junior engineers and collaborate across teams to enhance system resilience.
The Site Reliability Engineer leads efforts to ensure the stability, scalability, and performance of systems and platforms by embedding reliability and automation principles into software lifecycle stages. Drives proactive risk identification and mitigation strategies for critical systems.
Is this about you?
You are an independent problem-solver with a passion for system reliability and automation. You enjoy working in a dynamic environment and collaborating with others to improve system performance.
Bachelor’s or Master’s degree in Computer Science, Engineering, or related fields. Advanced certifications in cloud technologies (e.g., Azure Solutions Architect, AWS Certified DevOps Engineer) or Kubernetes (e.g., CKA, CKAD).
5–7 years of impactful experience in software engineering or infrastructure management, with demonstrated contributions to complex digital products or systems.
Expertise in cloud platforms and deep understanding of networking, security, and operations management, with a balance of software and infrastructure skills.
Mastery of Kubernetes and infrastructure as code tools like Terraform, Ansible, or similar.
Experience designing and operating large-scale distributed systems.
Excellent software engineering or infrastructure design skills, coupled with leadership in agile practices and delivery.
Thrives in ambiguity, taking ownership to solve challenging problems and mentor junior engineers.
You’ll be responsible for
Designs and implements scalable, reliable solutions, mentors junior engineers, and collaborates across teams to improve observability and system performance.
Cloud Architecture: Lead the design of scalable cloud solutions for medium-to-large projects. Balance conflicting performance and availability demands.
Release Management: Define comprehensive branching and deployment strategies. Automate complex integration pipelines.
Operational Excellence: Lead incident responses. Design robust support models and continuously refine SLOs and SLIs for critical systems.
Monitoring & Capacity Planning: Oversee system monitoring strategy. Plan for future capacity and scaling needs.
Mentorship: Actively guide engineers across multiple teams. Share best practices and improve documentation standards.
Collaboration: Influence cross-functional decisions, communicate technical trade-offs clearly to leadership and stakeholders, contributing beyond core responsibilities when needed
This is where you’ll work
You will be part of a collaborative, cross-functional team focused on maintaining and improving system reliability. You’ll work closely with engineers, operations, and business stakeholders to ensure critical systems remain scalable and performant. Our team fosters a culture of learning, mentorship, and proactive problem-solving, where your contributions will have a direct impact on our technology landscape.
What we have to offer

Gross annual salary between €79.000 and €108.000

FlexBudget

Personal and professional growth

Hybrid working: home, office or abroad
Want more information about our terms of employment?

Work that works for you and the climate
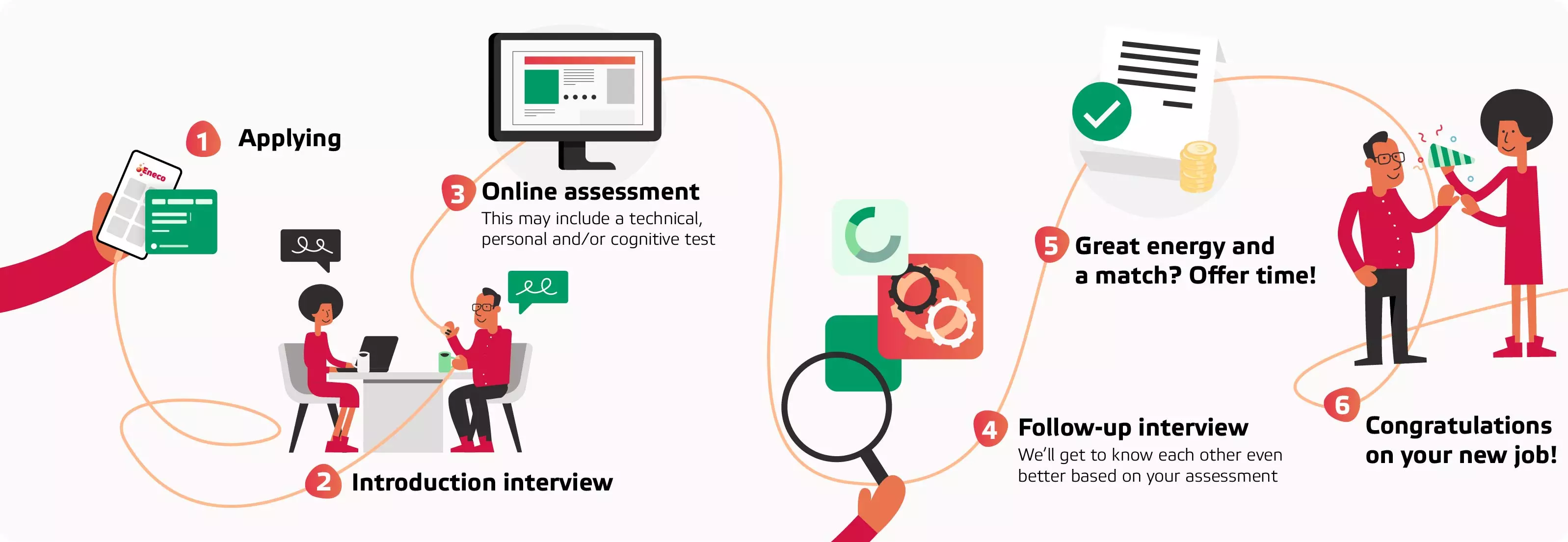
The phases of our application procedure:
Want to know more about this job function?
Please reach out to our recruiter.

Questions about the application procedure
Faisal Faik
